AIモデルの急速な進化に伴い、コンピューティングパワーの成長は、単なるGPU性能の競争から「システムレベルのインフラ競争」へと拡大しています。データセンター内の通信効率、帯域幅、レイテンシ制御が、AIクラスター性能の上限を決める重要な変数となりつつあり、高速インターコネクトや光ネットワーク技術が中心的な役割を担うようになっています。
この変化を背景に、Marvellのビジネスフォーカスは、従来のストレージやネットワークチップから、AI主導のデータセンターインフラエコシステムへと徐々に移行しています。以下の分析では、高速インターコネクト需要、カスタムASICの成長、光インターコネクトの進化、CPOアーキテクチャ、競合環境、将来の開発方向性など、多角的な観点からAIバリューチェーンにおける同社のポジションを詳しく解説します。
MarvellのカスタムASICビジネスが急速に成長している理由
近年、Marvellで最も急成長しているビジネスの一つが、カスタムASIC(特定用途向け集積回路)です。
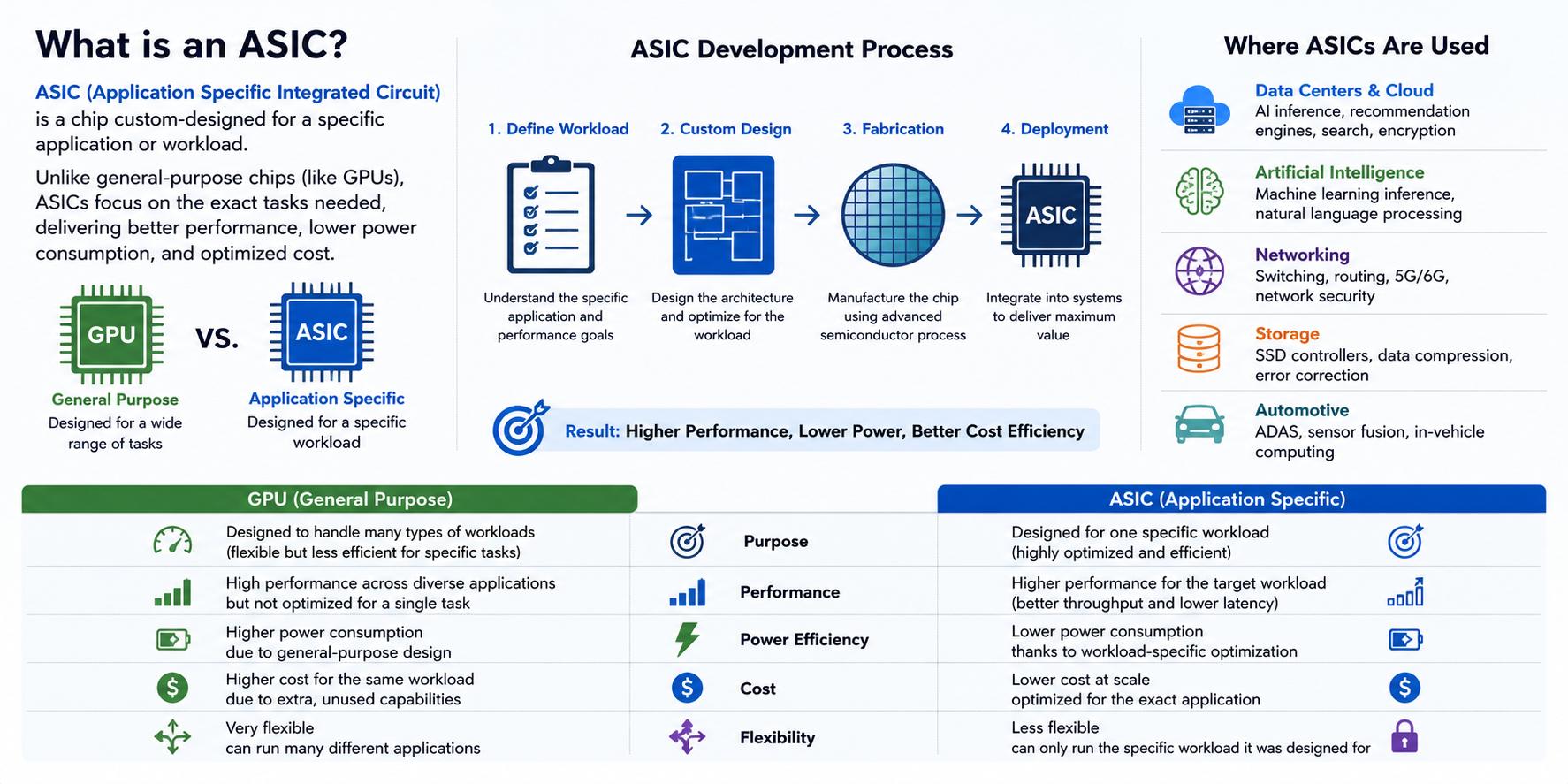
ASICは、特定のアプリケーション専用に設計されたチップです。汎用GPUとは異なり、ASICは多種多様な計算タスクを処理する必要はありません。その代わり、顧客の特定のワークロードに最適化されており、性能、消費電力、コストのバランスをより適切に実現できます。
主要なクラウドプロバイダーにとって、自社でのASIC開発は重要なトレンドとなっています。例えば、AWSはTrainiumおよびInferentiaシリーズのAIチップを投入し、GoogleはTPUを継続的に改良し、MicrosoftはMaia AI Acceleratorをリリースしました。これらのチップは最終的には各社のブランドで販売されますが、その開発には多くの場合、専門的なチップ設計企業の深い関与が必要です。
Marvellはこのプロセスで重要な役割を果たしています。同社は、顧客のニーズに合わせたASIC設計サービスをフルレンジで提供しており、アーキテクチャ設計、高速I/O、アドバンスドパッケージング、IP統合、その後の検証までをカバーしています。
標準的なチップビジネスと比較して、カスタムASICにはいくつかの明確な利点があります。
- 顧客とのコラボレーションサイクルが長い。初期設計から量産までには通常2〜3年かかります。一度量産に入れば、ライフサイクルは数年に及ぶことが多く、比較的安定した収益をもたらします。
- 顧客の粘着性が高い。ASICは顧客のソフトウェアエコシステム、データセンターアーキテクチャ、サプライチェーンと深く統合されているため、サプライヤーの切り替えコストが高く、パートナーシップがより長続きします。
- 収益性が高い。研究開発投資は大きいものの、製品の高度なカスタマイズ性により価格競争が制限されるため、長期的な粗利益率は標準製品よりも一般的に良好です。
世界的なクラウドプロバイダーがAIへの資本支出を増やし続ける中、カスタムASIC市場は成長を続けると予想され、Marvellの最も重要な長期的成長ドライバーの一つとなっています。
光インターコネクトがAIクラスター開発の必然的な方向性である理由
GPUがAIデータセンターの頭脳であるとすれば、光インターコネクトはその神経系です。
かつて、ほとんどのサーバーは主に銅線ケーブルを介した電気信号伝送に依存していました。しかし、ネットワーク速度が上昇するにつれて、銅線ケーブルは明らかな限界に直面しています。
- 伝送距離が限られている。400G、800G、さらには将来の1.6Tの速度では、銅線ケーブルにおける信号減衰がより深刻になり、ますます複雑な信号補償が必要になります。
- 消費電力が急速に増加する。高速電気インターコネクトは、信号増幅と等化にかなりのエネルギーを消費します。大規模なAIデータセンターでは、このエネルギー使用量が運用コストの主要な構成要素となっています。
- 高速電気接続は電磁干渉の影響も受けやすく、全体的な安定性を損なう可能性があります。
対照的に、光インターコネクトは、より高い帯域幅、より低いレイテンシ、より低いエネルギー消費、より長い伝送距離を提供し、従来の電気インターコネクトに取って代わる自然な選択肢となっています。
Marvellは長年にわたり光インターコネクト分野で積極的に活動しており、製品には高速DSP、PAM4信号処理、光モジュールコントローラー、および関連チップが含まれており、AIデータセンター内部の重要な通信リンクをカバーしています。
現在、400Gは大規模データセンターの主要な展開基準となっており、800Gは急速に採用が進んでおり、1.6T光モジュールは今後数年のうちに商業化されると予想されています。これは、業界チェーン全体に依然として大きなアップグレードの余地があることを意味します。
AIクラスターの規模が拡大し続けるにつれて、光インターコネクトはデータセンター間の接続からラック内、さらにはチップ間の接続へと拡大しており、Marvellにとって持続的な成長機会を生み出しています。
CPOが次世代AIネットワークアーキテクチャと見なされる理由
従来の光モジュールに加えて、近年最も注目されている新しい方向性の一つがCPO(Co-Packaged Optics)です。
従来のネットワークアーキテクチャでは、スイッチチップと光モジュールは通常、別々に配置され、データ伝送に高速電気接続が必要でした。帯域幅が増加するにつれて、これらの電気接続はより多くの電力を消費するだけでなく、信号損失も引き起こします。
CPOの中核となるアイデアは、光コンポーネントをスイッチチップと直接パッケージ化し、光信号をコンピューティングコアに近づけることです。これにより、エネルギー消費を大幅に削減し、全体の帯域幅密度を向上させます。
数万基のGPUを収容する将来のAIスーパークラスターにとって、このアーキテクチャはネットワーク効率をさらに改善することが期待されています。
Marvellは、高性能スイッチチップ、DSP、光エンジン、アドバンスドパッケージング機能など、CPO関連技術に着実に投資しており、次世代AIネットワークアーキテクチャにおけるより強力なポジションの確保を目指しています。
CPOはまだ商業化の初期段階にありますが、データセンターの消費電力上昇により、市場はこれを将来の高速ネットワークにおける重要な技術的方向性と見なしています。
AIインフラのアップグレードがMarvellに継続的な利益をもたらす仕組み
AIコンピューティングパワーの成長は、GPUの出荷増加だけをもたらすのではなく、インフラチェーン全体の同時拡大を促進します。
モデルパラメータが増加し、GPUの数が増えるにつれて、データセンターはより多くのスイッチチップ、光モジュール、高速ネットワークコントローラー、インターコネクトソリューションを調達する必要があります。新しいGPUのバッチごとに、通常、完全なサポートネットワークシステムが必要です。その結果、AIインフラ投資は、GPUを購入するだけから、コンピューティング、ネットワーキング、ストレージ、電源、冷却をカバーするシステムレベルの構築へと進化しました。
Marvellはまさにこれらの「コンピューティングではないが不可欠な」インフラ分野に対応しています。GPUクラスターの規模が拡大するにつれて、ネットワーク機器がデータセンターの総コストに占める割合は増加しており、これは高速インターコネクト市場にまだ大きな成長の余地があることを意味します。
同時に、AI投資とグローバルな資産配置において、市場参加者はダイナミックなリバランスのためにクロスマーケット取引能力にますます依存しています。例えば、Gateが提供する株式取引プラットフォームは、米国株、香港株、韓国株の24時間取引をサポートしており、投資家は異なる市場時間帯にわたってAI関連資産の価格変動と資金フローを継続的に追跡できます。これにより、グローバルなAIインフラサイクルのローテーション機会に、より柔軟に参加できるようになります。
このメカニズムは、AI産業チェーンのグローバルな相互接続を強化し、Marvellのようなインフラ企業の市場価格付けをより連続的にします。投資家は、単一市場の取引時間に制限されることなく、グローバルなAI業界の変化に応じてポジションをより迅速に調整できます。
Marvell、Broadcom、NVIDIAの違いは何か
3社はいずれもAIインフラの主要プレーヤーと見なされていますが、その中核的なポジションは明確に異なります。
| 企業 | 中核的ポジション | 主要製品 | AI産業チェーンにおける役割 | 成長ドライバー |
|---|---|---|---|---|
| NVIDIA | AIコンピューティングレイヤー | GPU、CUDAソフトウェアプラットフォーム、NVLink、DGXシステム | AIコンピューティングコアを提供 | AIモデルトレーニングと推論需要の成長、GPU出荷増加 |
| Broadcom | ネットワーキングとカスタムASIC | スイッチチップ、ネットワークチップ、カスタムASIC、PCIeスイッチ | AIデータセンターネットワーキングとクラウドベンダーカスタムチップを構築 | ハイパースケーラークラウドベンダーの設備投資、高速ネットワークアップグレード、ASIC需要の成長 |
| Marvell Technology | 高速インターコネクトと接続レイヤー | 光インターコネクト、DSP、スイッチチップ、ストレージインターコネクト、カスタムASIC | AIデータセンター内のコンピューティング、ストレージ、ネットワーキングを接続 | AIクラスター規模拡大、光ネットワークアップグレード、CPO商業化、ネットワーク複雑性の増大 |
NVIDIAは主にAIコンピューティングレイヤーを担当し、GPU、CUDAソフトウェアエコシステム、および完全なAIコンピューティングプラットフォームを提供しており、今日のAIコンピューティングパワーの中核的プロバイダーです。
Broadcomは、スイッチチップ、ネットワークインフラ、カスタムASICに重点を置いており、エンタープライズネットワーキングとハイパースケールクラウドデータセンターに深い専門知識を持ち、AI ASIC市場における主要な競合相手です。
Marvellは、高速インターコネクト、光ネットワーク、DSP、データセンタースイッチング、ストレージインターコネクト、カスタムASICなど、接続レイヤーに重点を置いています。
簡単に言えば、NVIDIAは「計算」を担当し、BroadcomとMarvellは「接続」を担当します。
このポジショニングは、Marvellの成長ロジックがGPU製品サイクルに完全に依存するのではなく、AIデータセンターの全体的な拡大とそのネットワークの複雑性の増大からより多くの恩恵を受けることを意味します。AIクラスターがハイパースケールに向けて拡大し続けるにつれて、接続レイヤーの重要性は高まり続けると予想されます。
AIインフラ市場にはどのような課題がまだ存在するか
業界の長期的な見通しは明るいものの、Marvellが事業を展開する市場には依然として不確実性が存在します。
高速ネットワーキング製品の研究開発ハードルは非常に高いです。先進的なプロセスノード、SerDesテクノロジー、高速パッケージングに至るまで、各世代は継続的かつ多額の研究開発投資を必要とし、技術革新のペースは加速しています。
顧客集中度は比較的高いです。Marvellの主な顧客はほとんどが大手グローバルクラウドサービスプロバイダーであり、その設備投資サイクルは同社の受注成長に直接影響します。AI投資サイクルが減速すれば、関連収益に影響が出る可能性があります。
テクノロジーロードマップも流動的なままです。800Gから1.6Tへのアップグレードであれ、CPOの商業化であれ、業界チェーン全体が協調して成熟する必要があります。新技術の採用が予想よりも遅ければ、短期的な市場パフォーマンスは変動する可能性があります。
AIインフラ分野における競争も激化しています。Broadcom、NVIDIA、Astera Labsなどの企業は、高速インターコネクトとネットワークチップに積極的に拡大しており、将来の競争が依然として激しいものであることを確実にしています。
MarvellのAIビジネスにおける将来の開発方向性
今後、Marvellの成長焦点は3つの分野に集中する可能性があります。
- カスタムASICビジネスをさらに拡大し、より多くのハイパースケールクラウドプロバイダーとの長期的なパートナーシップを確立し、AI推論チップに対する需要の増加から利益を得る。
- 光インターコネクトとCPOの商業化を加速する。AIデータセンターネットワークがアップグレードを続ける中、次世代高速光ネットワークは新たな成長エンジンになると予想される。
- ネットワークインフラのプラットフォーム化を推進する。スイッチチップ、高速インターコネクト、システムレベルのネットワーク最適化に至るまで、Marvellは個々のチップ製品だけでなく、より包括的なデータセンター接続ソリューションを提供することを目指している。
AIアプリケーションが大規模トレーニングから推論展開へと移行するにつれて、将来のデータセンターでは、全体的なエネルギー効率、コスト管理、システム利用率がより重視されるようになるでしょう。単にGPU性能を向上させるのではなく、より低い消費電力とより高い効率で数万のコンピューティングノードを接続することが重要な課題となり、それがまさにMarvellが長年にわたって注力してきた分野です。
まとめ
AI産業チェーンにおけるMarvellの価値は、コンピューティングパワーを直接提供することではなく、効率的なAIシステム運用を可能にする接続性を構築することにあります。高速スイッチチップや光インターコネクトからDSPやカスタムASICに至るまで、同社はAIデータセンター内部の複数の重要なインフラリンクをカバーしています。
グローバルなAI投資が継続するにつれて、データセンター建設は生のコンピューティングパワーへの焦点からシステムレベルの最適化へと移行しています。ネットワーク帯域幅、通信効率、消費電力制御、高速インターコネクトの重要性が増すにつれて、Marvellは従来のネットワークチップメーカーからAIインフラ接続レイヤーの主要プレーヤーへと変貌を遂げました。
今後、光ネットワーキング、CPO、カスタムASICなどの技術が成熟し続けるにつれて、MarvellはグローバルなAIインフラアップグレードサイクルから利益を得る有利な立場にあり、高速インターコネクトとインテリジェントネットワーキングの分野で長期的な成長モメンタムを維持することが期待されます。
共有
内容
6つのアドレスがCowswap経由で12,128 ETHを購入し、Tornado Cashに転送。
Binance Life Meme Coinが20%以上急騰、$0.91に到達
Bio ProtocolがOpenLabsを立ち上げ、USDC利回りメカニズムで科学研究プロジェクトを支援
米国のM2マネーサプライが5月に過去最高の23.05兆ドルを記録、初めて23兆ドルを超える
トレーダーAnsemのANSEMポートフォリオは1週間で $193M の利益を得た;初期のトレーダーの退出コストは238万ドルだった。


関連記事

Render、io.net、Akash:DePINハッシュレートネットワークの比較分析

AI分野におけるRenderの申請理由:分散型ハッシュレートが人工知能の発展を支える仕組み

USD.AI 収益源分析:AIインフラ借入資金による収益創出の仕組み

USD.AIトケノミクス:CHIPトークンの使用事例およびインセンティブメカニズムのデプス分析

PharosはRWAをどのようにオンチェーン化するのか、RealFiインフラのロジックを詳細にご紹介します
